A new paper, HarnessX, argues that an agent harness should evolve itself from its own execution traces. The obvious worry with anything that rewrites its own scaffolding is that it quietly breaks what already worked. We rebuilt the paper's core in 470 lines of Python to find out what stops that. The answer is a single deterministic check, and when we removed it the harness climbed to a perfect score and then fell off a cliff.
What we did
HarnessX treats a harness as a typed pipeline of "processors" bound to eight fixed hook points, edited by a substitution algebra (insert, replace, remove) that has to stay well-typed. On top of that sits AEGIS, a loop that reads execution traces and proposes edits: a Digester turns failures into evidence, a Planner ranks what to try, an Evolver writes the edit, and a Critic and Gate decide whether to keep it. We reproduced that symbolic core, dependency-free, no model calls, deterministic, five seeds, under a second to run. We did not reproduce the paper's headline +14.5% benchmark gain, which needs five real agent benchmarks plus reinforcement learning. We went after a narrower question that is cheap to answer: is the gate actually the thing doing the work?
Our test environment is deliberately small. Tasks each need a random
subset of seven capabilities and are solved only if the harness provides
them. One tempting edit, a faster budget controller, shares a
mutual-exclusion group with the good one but breaks retry as
a side effect: a realistic conflicting scaffold. The meta-agent is a
deterministic heuristic, so we are measuring the gate, not generation
quality. It attempts that conflicting swap late in the run, once the
harness has already matured.
Why it was worth doing
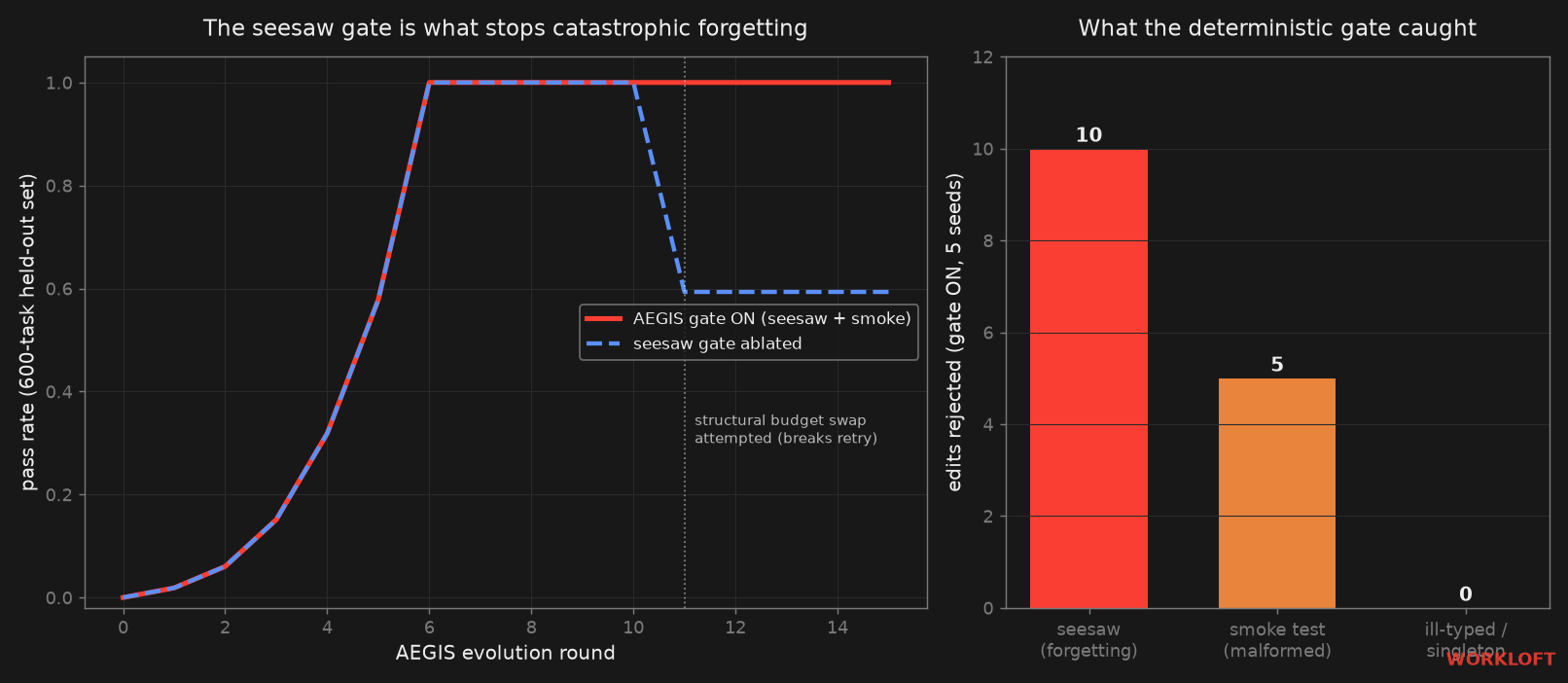
The result is clean. With the full gate, AEGIS builds the harness up to a
1.000 pass rate and holds it. The conflicting budget swap
is attempted twice per seed and rejected all ten times, because committing
it would regress the roughly 40% of tasks that need retry.
Ablate that single check, the seesaw constraint, and the identical run
climbs to 1.000, then falls to 0.593 the moment the swap commits
and never recovers. The Planner has already marked budget as
attempted, so it never heals itself. That is catastrophic forgetting,
reproduced from the mechanism alone, and it is exactly the failure the
paper's seesaw constraint exists to prevent.
The cheaper guarantee held too. A build and smoke test on each proposed edit caught every malformed processor: zero committed with the test on, five committed across the seeds once we removed it. And the substitution algebra kept its invariants under test, with ill-typed insertions and singleton-group collisions raising rather than silently corrupting the pipeline. That last property is what lets a partly-blind meta-agent propose edits safely in the first place.
What's still off
This is the symbolic core on a synthetic environment, not the benchmark number. Our meta-agent is a deterministic heuristic, so we say nothing about whether a real model proposes good edits. We only show that given proposals, the deterministic gate is what separates monotone improvement from regression. The +14.5% gain, the co-evolution with model training, and the inverse-scaling pattern all stay unverified here.
What reproduces, clearly and for almost no money, is the paper's central safety argument. Trace-driven self-improvement is only safe because a deterministic gate refuses to let it forget. For anyone building agents that edit their own scaffolding, that is the line to hold: keep a hard, non-negotiable check that no change may regress a task you already solved.